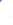.NET XML Best Practices
Part I: Choosing an XML API
by Aaron Skonnard
As someone who has spent the past several years learning and using the
various XML APIs available throughout the industry, I can honestly say
that the .NET implementations are the best I've seen in terms of productivity,
efficiency, and extensibility. The .NET XML framework provides support
for all of the W3C-stamped XML specifications including:
- XML 1.0
- Namespaces in XML
- DOM Level 2
- XPath 1.0
- XSLT 1.0
- XML Schema
All of the above have achieved the W3C Recommendation status, which means
that the specifications have been approved by a majority of the consortium
members. Once a specification becomes a W3C Recommendation, it cannot
be changed without repeating the development process and receiving consensus
once again. The fact that XPath, XSLT,
and XML Schema were all finalized within the last
year makes it excellent timing for Microsoft to build .NET on top of a
solid XML foundation, which includes these standards.
In addition to these W3C specifications, the .NET XML framework also
provides support for several other XML-related technologies that don't
share the same level of acceptance but which are quickly gaining mind-share
as they continue to evolve:
Streaming XML APIs (like SAX)
Most of these XML-related technologies/specifications will undergo heavy
churn for the years to come. Nevertheless, providing support for them
today offers too many advantages to pass up.
The .NET XML framework provides API support for all of the XML-related
technologies listed above, both new and old. This gives the .NET XML developer
a powerful tool chest for solving a wide array of problems. It's ironic
that although this tool chest was designed to simplify things, the surplus
of choices often ends up confusing developers. However, as you become
familiar with the .NET XML framework, you'll see that in most situations
the "right" technology choice is obvious.
This article is the first part of a three-part series on the .NET XML
framework. In this first part, we'll cover how to choose the right XML
API for both reading and writing XML documents. Then, in the following
two parts, we'll walk through practical code examples of each approach
discussed in this piece.
Reading XML Documents
The most basic task in XML programming is to read and process an XML
1.0 document. When I use the term, "XML 1.0 document", I'm referring to
a physical XML 1.0 byte stream that contains angle brackets and namespace
declarations as shown here:
<x:name xmlns:x="http://example.org/name">
<first>Aaron</first>
<last>Skonnard</last>
</x:name>
I'll try to be precise with my terminology because the term "XML document"
can refer to either a physical document (like the one above) or a logical
document (like a DOM tree). The term "XML 1.0 document" more precisely
refers to a physical byte stream of XML content.
The task of reading and processing an XML 1.0 document consists of several
steps that can be divided into the layers shown in Figure 1:

Figure 1: XML Processing Layers in .NET
This image illustrates that developers can choose to work with XML at
a variety of levels, with the bottom of the stack representing the lowest
productivity level and the top of the stack the highest. And to further
complicate things, the middle levels are full of different choices for
developers to use.
Parsing the XML 1.0 Byte Stream
The bottom-most layer is the task of parsing the XML 1.0 byte stream
according to the XML 1.0 and Namespace specifications. This task is typically
handled by an XML parser that hides the complexities of the XML 1.0 syntax
by serving up the document as a logical-tree structure through higher-level
APIs.
One of the reasons that XML has become so popular is because there are
so many of these low-level parsers freely available to use. In .NET, the
XmlTextReader class provides this type of XML 1.0
parsing functionality. There are really no other choices available at
this level but because of the framework's extensible design, more could
easily be added in the future.
Processing the Logical Tree via XML APIs
The next layer in the stack requires developers to choose an XML API
for processing the logical tree structure exposed by the parser. There
are many different XML API flavors available today but the two most common
are: 1) streaming and 2) traversal-oriented.
The most common streaming API used today is the Simple
API for XML (SAX). Microsoft introduced support for SAX
in MSXML 3.0 but then determined that the SAX-based programming model
was too obscure and unnecessarily difficult for the majority of their
developer community. So to provide .NET developers with a more intuitive
alternative, Microsoft introduced a new streaming API through the XmlReader
class hierarchy.
The main difference between XmlReader and SAX
is that the former allows the client to control the flow of execution
by pulling the nodes from the stream one at a time while with the latter,
the processor is in control, pushing the nodes back to the client one
node at a time. This significant difference makes XmlReader
much easier to use for most Microsoft developers that are used to working
with firehose (forward-only/read-only) cursors in ADO.
Since SAX has not been stamped by any of today's
standards bodies, most do not consider it a standard in W3C-speak, or
in the same group as the other technologies mentioned earlier. Therefore,
Microsoft's decision to not directly support SAX
but rather to provide an easier-to-use alternative for their developers
is completely reasonable as far as standards are concerned.
XML Schema and DTD validation
is also provided at the streaming level through a specialized XmlValidatingReader
class, which can be used in conjunction with any XmlReader
implementation including XmlTextReader.
The most common traversal-oriented API used today is the Document
Object Model (DOM), which is available in .NET through the XmlNode
class hierarchy. In .NET, XmlNode-based trees are
built via underlying XmlReader streams. These trees,
however, remain in memory until the client is finished with them. DOM
trees are completely dynamic and can be traversed in a variety of ways.
Most developers working with XML are familiar with the DOM
API since it has been around the longest. The DOM
is considered the "easiest to use" by many developers but that simplicity
comes with a cost.
In addition to the DOM, Microsoft introduced another
traversal-oriented API called XPathNavigator. XPathNavigator
makes it possible to traverse a logical tree (as defined by the XPath
specification) using a cursor model, which gives the underlying implementation
more options in terms of how the tree is actually stored. XPathNavigator
can sit on top of an in-memory DOM tree but it
can also sit on top of other non-XML data stores if desired. And as its
name suggests, XPathNavigator also supports higher-level
services like XPath expressions and XSLT
integration.
Simplifying Code via XPath, XSLT,
XSD
XML also comes with several higher-level services that offer additional
functionality to the APIs just mentioned. The most important of these
are XPath, XSLT, and XML
Schema, all of which are supported today in .NET. Most XML developers
use at least one or more of these services in most of their code because
they can greatly boost productivity.
XPath can be used in conjunction with the standard
.NET DOM implementation as well as through XPathNavigator
but not with today's XmlReader implementations
(at least not out of the box). Using XPath with
the DOM API or XPathNavigator
is a no-brainer because it greatly simplifies the traversal code commonly
written with these APIs. I for one never write DOM
code without the help of XPath expressions sprinkled
throughout.
Also, if you write a lot of code that transforms XML documents into some
other format, XSLT may increase your productivity
if the XSLT learning curve isn't too steep. XSLT
can be used in .NET through the XslTransform class,
which is capable of executing transformations on top of any XPathNavigator
implementation, such as the one that sits on top of DOM
trees.
In addition to the XPathNavigator implementation
for standard DOM trees, .NET provides an optimized
alternative called XPathDocument. XPathDocument
does not implement the W3C DOM specification but
rather a more efficient internal tree structure that can be traversed
through XPathNavigator. So if you're writing a
lot of XPath or XSLT intensive
code, XPathDocument might offer you some additional
performance benefits.
And finally, XML Schema makes it possible to annotate
logical XML trees with application type information. This type information
can be used for 1) validation, and 2) type reflection. Validation can
greatly simplify the amount of error handling that you need to build into
your XML processing code. Reflection, on the other hand, makes it possible
to automatically generate the processing code (see System.Xml.Serialization
for more details). In .NET, you must use XmlValidatingReader
if you wish to leverage either of these powerful concepts.
Reading Choices
The previous sections describe all of the .NET XML API choices available
at the different processing layers shown in Figure 1. When you start writing
the application logic required to process an XML file, you must first
decide which of these choices is "right" for you. As Figure 1 illustrates,
you can choose to work close to the low-level XML parser, through XmlTextReader,
or at more abstract levels through layered APIs and services.
The choice is not always easy since there are so many things to consider.
The following table helps narrow things down by describing the most common
scenarios and the pros and cons of each.
| CHOICES |
PROS |
CONS |
| XmlTextReader |
-Fastest
-Most efficient (memory)
-Extensible |
-Forward-only
-Read-only
-Requires manual validation |
| XmlValidatingReader |
-Automatic validation
-Run-time type info
-Relatively fast & efficient
(compared to DOM) |
-2 to 3x slower than XmlTextReader
-Forward-only
-Read-only |
| XmlDocument (DOM) |
-Full traversal
-Read/write
-XPath expressions |
-2 to 3x slower than XmlTextReader/XmlValidatingReader
-More overhead than XmlTextReader/XmlValidatingReader |
| XPathNavigator |
-Full traversal
-XPath expressions
-XSLT integration
-Extensible |
-Read-only
-Not as familiar as DOM |
| XPathDocument |
-Faster than XmlDocument
-Optimized for XPath/XSLT |
-Slower than XmlTextReader |
Figure 2: .NET API Choices for Reading XML-Pros and Cons
As you can see, there is a fundamental tradeoff between performance/efficiency
and productivity when comparing the different choices. The following figure
roughly describes the trade-off between processing time and productivity
for performing some common XML processing tasks.

In general, as productivity increases, so does processing time. The same
is true for memory overhead only the difference between XmlTextReader
and XmlDocument is a bit more severe.
Choosing a configuration of .NET classes usually boils down to the following
three decisions:
- What kind of reader should I use?
- Should I load the tree into memory?
- XmlDocument or XPathDocument?
Making the Decision
The first choice is what kind of reader to use. If the data is in XML
1.0 format (the general case), you have no choice but to use XmlTextReader
to process the byte stream. However, if you also need XML
Schema/DTD validation or wish to access
XML Schema type information at runtime, you need
to layer XmlValidatingReader over an XmlTextReader
instance and use it instead.
It's also possible to read data that's not in XML 1.0 format as if it
were an XML document through custom XmlReader or
XPathNavigator implementations. For more details
on how to write this type of custom XML provider see my article in the
Septermber
2001 issues of MSDN Magazine (see [1] in the References section at
the bottom of this page). The following figure illustrates the decision
tree for choosing a reader:
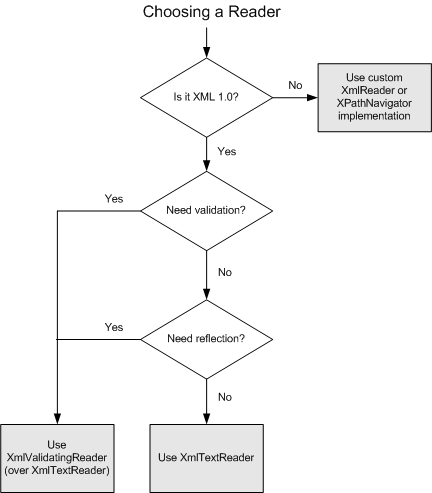
The second choice is whether to load the document into memory. This decision
depends mostly on whether you plan to use any higher-level XML services
like XPath or XSLT. If you
do, you must load the document into memory today. But even when you don't
plan to use these services, if your schema is fairly complex or if the
document instances are typically small, you might choose to load the document
into memory anyway. The following decision tree illustrates these considerations:
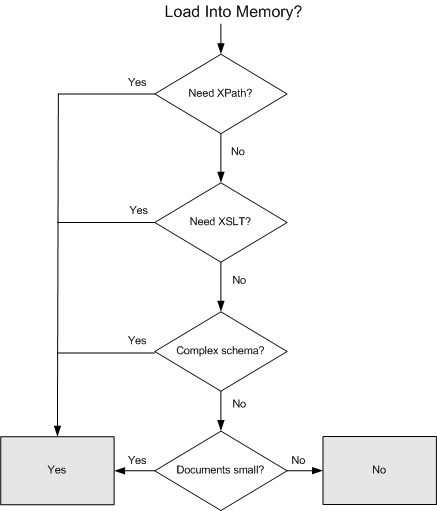
If you decide against loading the document into memory, you should stop
here and write your code in terms of the reader you already chose. But
if you decide to load the document into memory, you also need to choose
the right in-memory structure.
Today there are only two in-memory structures available in .NET, XmlDocument
(the standard DOM implementation) and XPathDocument
(a tree optimized for XPath/XSLT).
Deciding between these mostly depends on how much you care about performance,
programming ease, and future extensibility as illustrated by this decision
tree:
In terms of performance, XPathDocument offers
XPath and XSLT optimizations.
XPathDocument implements the XPathNavigator
interface over its more efficient tree structure. XmlDocument,
however, is typically easier to use since it implements both the standard
DOM interfaces as well as XPathNavigator.
Since most developers are already familiar with the DOM
interfaces, you'll sacrifice a bit of short-term productivity if you choose
to use XPathNavigator for the performance benefits.
Also, writing code via XPathNavigator is generally
a good idea if you care about taking advantage of future extensions. Since
XPathNavigator is much easier to implement than
the DOM API, you're more likely to see new-and-improved
custom implementations down the road.
Writing XML Documents
Luckily the choices for writing XML documents are nowhere near as complex
as those for reading XML documents. For generating XML documents you really
only have two API choices: XmlTextWriter and the
DOM.
Unlike XmlTextReader, XmlTextWriter
is actually more intuitive for many developers than the DOM,
especially for those used to working with SAX.
Using XmlTextWriter to generate a document feels
a lot like the SAX ContentHandler interface since
a sequence of method calls represents a logical XML document. As with
SAX, the key benefit to XmlTextWriter
is that the resulting document doesn't need to be buffered in memory.
Instead it can be written directly into the output stream as the document
is generated. This makes XmlTextWriter much more
efficient than the DOM and fortunately it's still
quite easy to use.
With the DOM, you build a document into an in-memory
object graph. Then you can serialize the object graph out as XML 1.0 through
a variety of mechanisms, which are all actually built on top of XmlTextWriter.
Since XmlTextWriter is more efficient and there
isn't a huge productivity tradeoff, you would probably only choose to
use the DOM if you need to work with the document
in-memory before producing the XML 1.0 byte stream.
Writing Choices
The following table helps narrow things down by describing the tradeoffs
between XmlTextWriter and the DOM
approach:
| CHOICES |
PROS |
CONS |
| XmlTextWriter |
-Fastest
-Most efficient, not buffered
-Familiar to SAX developers |
-You can't manipulate the document (forward-only
stream) |
| DOM |
-More flexibility in-memory
-Familiar to DOM developers |
-Slower and less efficient since buffered in-memory |
Figure 3: .NET API Choices for Writing XML-Pros and Cons
In general, if you're generating a stream of XML, use XmlTextWriter.
If you need to manipulate the document before serializing it, use the
DOM.
Conclusion
The .NET XML framework offers a wide-array of API choices for reading
and writing XML documents. The various choices often present a tradeoff
between performance/efficiency and productivity. The following two parts
of this series help illustrate these tradeoffs through practical code
examples of each approach discussed in this piece.
References
[1] XML in .NET: .NET Framework XML Classes and C# Offer Simple, Scalable
Data Manipulation, MSDN Magazine January 2001, http://msdn.microsoft.com/msdnmag/issues/01/01/xml/xml.asp,
by Aaron Skonnard
[2] Writing XML Providers for Microsoft .NET, MSDN Magazine September
2001, http://msdn.microsoft.com/msdnmag/issues/01/09/xml/xml0109.asp,
by Aaron Skonnard
About The Author
Aaron Skonnard is a consultant, instructor, and author specializing
in Windows technologies and Web applications. Aaron teaches courses for
DevelopMentor and is a columnist for Microsoft Internet Developer. He
is the author of Essential WinInet, and co-author of Essential XML: Beyond
MarkUp ( Addison Wesley Longman). Contact him at http://staff.develop.com/aarons.
|